 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolyglots or Multitudes? Multilingual LLM Answers to Value-laden Multiple-Choice Questions
Feb 05, 2026Multiple-Choice Questions (MCQs) are often used to assess knowledge, reasoning abilities, and even values encoded in large language models (LLMs). While the effect of multilingualism has been studied on LLM factual recall, this paper seeks to investigate the less explored question of language-induced variation in value-laden MCQ responses. Are multilingual LLMs consistent in their responses across languages, i.e. behave like theoretical polyglots, or do they answer value-laden MCQs depending on the language of the question, like a multitude of monolingual models expressing different values through a single model? We release a new corpus, the Multilingual European Value Survey (MEVS), which, unlike prior work relying on machine translation or ad hoc prompts, solely comprises human-translated survey questions aligned in 8 European languages. We administer a subset of those questions to over thirty multilingual LLMs of various sizes, manufacturers and alignment-fine-tuning status under comprehensive, controlled prompt variations including answer order, symbol type, and tail character. Our results show that while larger, instruction-tuned models display higher overall consistency, the robustness of their responses varies greatly across questions, with certain MCQs eliciting total agreement within and across models while others leave LLM answers split. Language-specific behavior seems to arise in all consistent, instruction-fine-tuned models, but only on certain questions, warranting a further study of the selective effect of preference fine-tuning.
EuroLLM-22B: Technical Report
Feb 05, 2026This report presents EuroLLM-22B, a large language model trained from scratch to support the needs of European citizens by covering all 24 official European Union languages and 11 additional languages. EuroLLM addresses the issue of European languages being underrepresented and underserved in existing open large language models. We provide a comprehensive overview of EuroLLM-22B's development, including tokenizer design, architectural specifications, data filtering, and training procedures. Across a broad set of multilingual benchmarks, EuroLLM-22B demonstrates strong performance in reasoning, instruction following, and translation, achieving results competitive with models of comparable size. To support future research, we release our base and instruction-tuned models, our multilingual web pretraining data and updated EuroBlocks instruction datasets, as well as our pre-training and evaluation codebases.
AdaptBPE: From General Purpose to Specialized Tokenizers
Jan 29, 2026Subword tokenization methods, such as Byte-Pair Encoding (BPE), significantly impact the performance and efficiency of large language models (LLMs). The standard approach involves training a general-purpose tokenizer that uniformly processes all textual data during both training and inference. However, the use of a generic set of tokens can incur inefficiencies when applying the model to specific domains or languages. To address this limitation, we propose a post-training adaptation strategy that selectively replaces low-utility tokens with more relevant ones based on their frequency in an adaptation corpus. Our algorithm identifies the token inventory that most effectively encodes the adaptation corpus for a given target vocabulary size. Extensive experiments on generation and classification tasks across multiple languages demonstrate that our adapted tokenizers compress test corpora more effectively than baselines using the same vocabulary size. This method serves as a lightweight adaptation mechanism, akin to a vocabulary fine-tuning process, enabling optimized tokenization for specific domains or tasks. Our code and data are available at https://github.com/vijini/Adapt-BPE.git.
The GDN-CC Dataset: Automatic Corpus Clarification for AI-enhanced Democratic Citizen Consultations
Jan 21, 2026LLMs are ubiquitous in modern NLP, and while their applicability extends to texts produced for democratic activities such as online deliberations or large-scale citizen consultations, ethical questions have been raised for their usage as analysis tools. We continue this line of research with two main goals: (a) to develop resources that can help standardize citizen contributions in public forums at the pragmatic level, and make them easier to use in topic modeling and political analysis; (b) to study how well this standardization can reliably be performed by small, open-weights LLMs, i.e. models that can be run locally and transparently with limited resources. Accordingly, we introduce Corpus Clarification as a preprocessing framework for large-scale consultation data that transforms noisy, multi-topic contributions into structured, self-contained argumentative units ready for downstream analysis. We present GDN-CC, a manually-curated dataset of 1,231 contributions to the French Grand Débat National, comprising 2,285 argumentative units annotated for argumentative structure and manually clarified. We then show that finetuned Small Language Models match or outperform LLMs on reproducing these annotations, and measure their usability for an opinion clustering task. We finally release GDN-CC-large, an automatically annotated corpus of 240k contributions, the largest annotated democratic consultation dataset to date.
Assessing the Political Fairness of Multilingual LLMs: A Case Study based on a 21-way Multiparallel EuroParl Dataset
Oct 23, 2025The political biases of Large Language Models (LLMs) are usually assessed by simulating their answers to English surveys. In this work, we propose an alternative framing of political biases, relying on principles of fairness in multilingual translation. We systematically compare the translation quality of speeches in the European Parliament (EP), observing systematic differences with majority parties from left, center, and right being better translated than outsider parties. This study is made possible by a new, 21-way multiparallel version of EuroParl, the parliamentary proceedings of the EP, which includes the political affiliations of each speaker. The dataset consists of 1.5M sentences for a total of 40M words and 249M characters. It covers three years, 1000+ speakers, 7 countries, 12 EU parties, 25 EU committees, and hundreds of national parties.
An Interdisciplinary Approach to Human-Centered Machine Translation
Jun 16, 2025Machine Translation (MT) tools are widely used today, often in contexts where professional translators are not present. Despite progress in MT technology, a gap persists between system development and real-world usage, particularly for non-expert users who may struggle to assess translation reliability. This paper advocates for a human-centered approach to MT, emphasizing the alignment of system design with diverse communicative goals and contexts of use. We survey the literature in Translation Studies and Human-Computer Interaction to recontextualize MT evaluation and design to address the diverse real-world scenarios in which MT is used today.
MockConf: A Student Interpretation Dataset: Analysis, Word- and Span-level Alignment and Baselines
Jun 05, 2025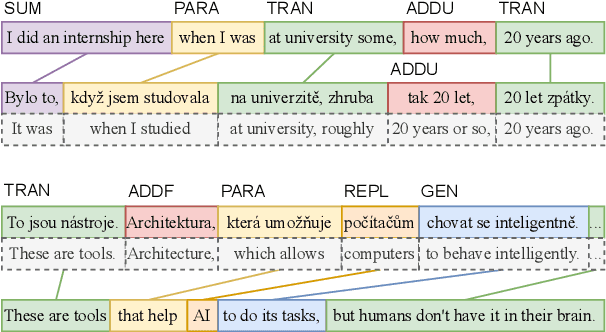
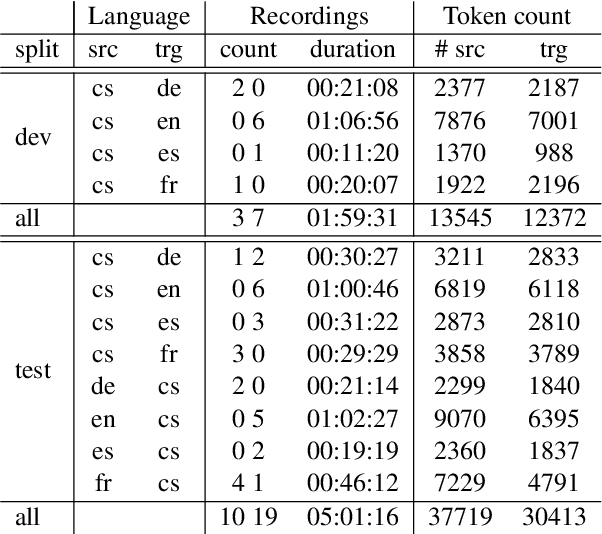
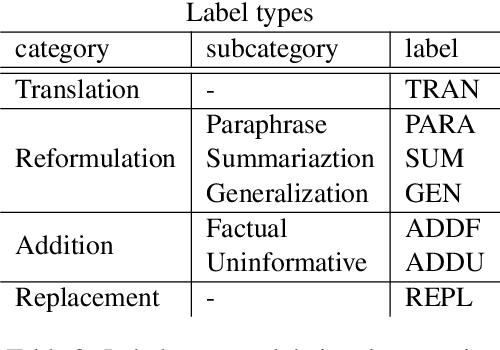
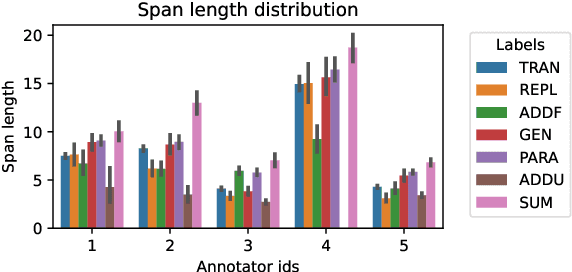
In simultaneous interpreting, an interpreter renders a source speech into another language with a very short lag, much sooner than sentences are finished. In order to understand and later reproduce this dynamic and complex task automatically, we need dedicated datasets and tools for analysis, monitoring, and evaluation, such as parallel speech corpora, and tools for their automatic annotation. Existing parallel corpora of translated texts and associated alignment algorithms hardly fill this gap, as they fail to model long-range interactions between speech segments or specific types of divergences (e.g., shortening, simplification, functional generalization) between the original and interpreted speeches. In this work, we introduce MockConf, a student interpreting dataset that was collected from Mock Conferences run as part of the students' curriculum. This dataset contains 7 hours of recordings in 5 European languages, transcribed and aligned at the level of spans and words. We further implement and release InterAlign, a modern web-based annotation tool for parallel word and span annotations on long inputs, suitable for aligning simultaneous interpreting. We propose metrics for the evaluation and a baseline for automatic alignment. Dataset and tools are released to the community.
Prompting LLMs: Length Control for Isometric Machine Translation
Jun 05, 2025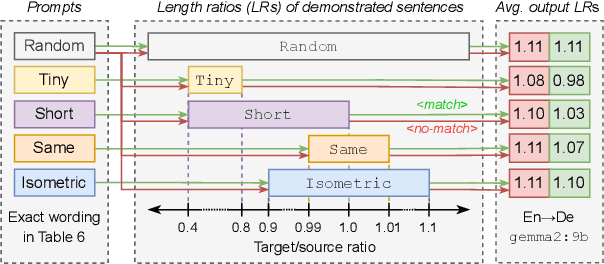

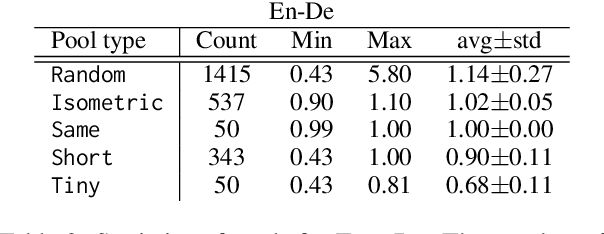
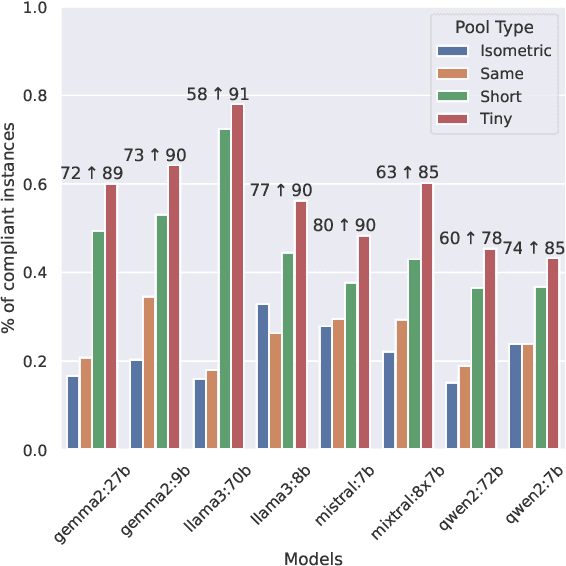
In this study, we explore the effectiveness of isometric machine translation across multiple language pairs (En$\to$De, En$\to$Fr, and En$\to$Es) under the conditions of the IWSLT Isometric Shared Task 2022. Using eight open-source large language models (LLMs) of varying sizes, we investigate how different prompting strategies, varying numbers of few-shot examples, and demonstration selection influence translation quality and length control. We discover that the phrasing of instructions, when aligned with the properties of the provided demonstrations, plays a crucial role in controlling the output length. Our experiments show that LLMs tend to produce shorter translations only when presented with extreme examples, while isometric demonstrations often lead to the models disregarding length constraints. While few-shot prompting generally enhances translation quality, further improvements are marginal across 5, 10, and 20-shot settings. Finally, considering multiple outputs allows to notably improve overall tradeoff between the length and quality, yielding state-of-the-art performance for some language pairs.
EuroLLM-9B: Technical Report
Jun 04, 2025



This report presents EuroLLM-9B, a large language model trained from scratch to support the needs of European citizens by covering all 24 official European Union languages and 11 additional languages. EuroLLM addresses the issue of European languages being underrepresented and underserved in existing open large language models. We provide a comprehensive overview of EuroLLM-9B's development, including tokenizer design, architectural specifications, data filtering, and training procedures. We describe the pre-training data collection and filtering pipeline, including the creation of EuroFilter, an AI-based multilingual filter, as well as the design of EuroBlocks-Synthetic, a novel synthetic dataset for post-training that enhances language coverage for European languages. Evaluation results demonstrate EuroLLM-9B's competitive performance on multilingual benchmarks and machine translation tasks, establishing it as the leading open European-made LLM of its size. To support open research and adoption, we release all major components of this work, including the base and instruction-tuned models, the EuroFilter classifier, and the synthetic post-training dataset.
Tracing Multilingual Factual Knowledge Acquisition in Pretraining
May 20, 2025Large Language Models (LLMs) are capable of recalling multilingual factual knowledge present in their pretraining data. However, most studies evaluate only the final model, leaving the development of factual recall and crosslingual consistency throughout pretraining largely unexplored. In this work, we trace how factual recall and crosslingual consistency evolve during pretraining, focusing on OLMo-7B as a case study. We find that both accuracy and consistency improve over time for most languages. We show that this improvement is primarily driven by the fact frequency in the pretraining corpus: more frequent facts are more likely to be recalled correctly, regardless of language. Yet, some low-frequency facts in non-English languages can still be correctly recalled. Our analysis reveals that these instances largely benefit from crosslingual transfer of their English counterparts -- an effect that emerges predominantly in the early stages of pretraining. We pinpoint two distinct pathways through which multilingual factual knowledge acquisition occurs: (1) frequency-driven learning, which is dominant and language-agnostic, and (2) crosslingual transfer, which is limited in scale and typically constrained to relation types involving named entities. We release our code and data to facilitate further research at https://github.com/cisnlp/multilingual-fact-tracing.